Picture this, a team is nearing the end of a five-week development effort on a small Data Mart project. A team of just three developers come to a screeching, abrubt halt because, in spite of dazzling specifications, and flawless design documentation, the code just doesn't play well together. At this stage the schedule goes out the window, because the team is engaged in the very unscientific process of wack-a-mole engineering to 'stamp out' the integration errors. The project and team in this example have just become witnesses to (as well as victims of) the Integration Bubble.
The root cause of our example Integration Bubble is the lack of putting the team's artifacts into an environment in which they would interract (dare I say integration server) for five weeks. It would stand to reason the most straightforward method for avoiding the IB is to integrate ALL of the executable artifacts early and often. There are a variety of tools to do this, Data Dude seems to be a promising IDE for the SQL Server database developer. I have also enjoyed success with putting Continuous Integration Processes, together by using Cruise Control .Net, Subversion and NAnt.
The key point here is the longer code for any project is unintegrated, the more unpredictable the integration process is going to be. To twist the Ben Franklin quote, "Don't intregrate tomorrow the defects you could solve today."
Friday, September 15, 2006
SSIS Configurations - Keep your friends close, your enemies closer
OK, the thinly-veiled "Godfather" paraphrase is only remotely associated with this topic, but stay with me there is a tie-in.
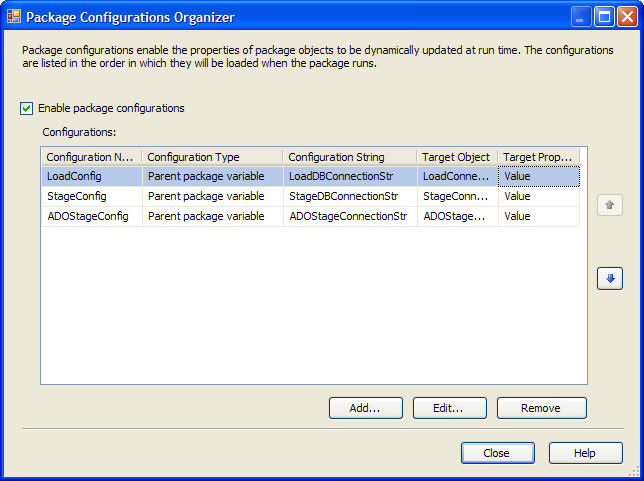
In a recent effort to use SSIS for the ETL processing of a data mart, I found a need to manage different configurations between production, test and individual developer sandboxes. This is the nail for which package configurations is the hammer. It soon became apparent that while we had indeed implemented "a" way of say, managing the different connection strings, for example. Time would tell that we had missed something significant.
Our initial strategy had been to use Parent Package configurations t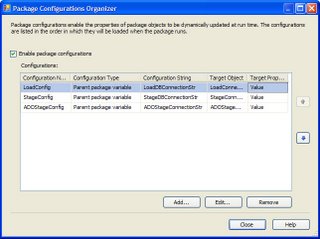 o set the Value property of the Connection String to the correct server, catalog, etc. It turns out this works, but is not without it's disadvantages. When you try to edit the package configured in this way, it is necessary to put the connection string in the Connection String Value property, because you are not in the execution environment, none has been set from the Parent Package. Additionally, Expressions have to be used with the Connection Manager to accomplish the setting of the target value property with the parent package variable. This is further complicated by having to 'remove' this Connection String value before committing the package to version control, lest the SSIS Server attempt to connect to the developer machine and not the server indicated by the package configuration.
o set the Value property of the Connection String to the correct server, catalog, etc. It turns out this works, but is not without it's disadvantages. When you try to edit the package configured in this way, it is necessary to put the connection string in the Connection String Value property, because you are not in the execution environment, none has been set from the Parent Package. Additionally, Expressions have to be used with the Connection Manager to accomplish the setting of the target value property with the parent package variable. This is further complicated by having to 'remove' this Connection String value before committing the package to version control, lest the SSIS Server attempt to connect to the developer machine and not the server indicated by the package configuration.
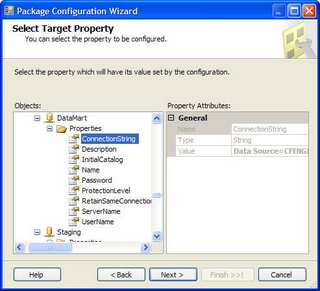
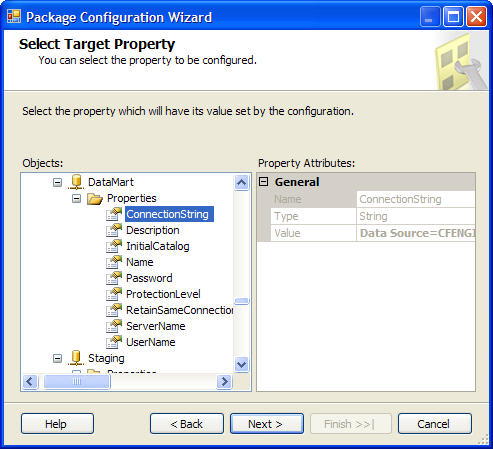
The better solution, it turns out, is to assign the Parent Package variable directly to the Connection String. This way, the true power of runtime package configuration is reali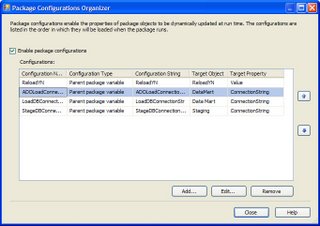 zed. Using this method, a developer can set one Connection String value in the child package, commit the package to revision control and be confident the Production, Test, etc configuration value will be used when the package executes. Furthermore, if all the developers on a team have identical properties for local execution, the values can remain set in the child package for the developer configuration, and overridden with the correct Production, Test, etc configuration at execution in those environments.
zed. Using this method, a developer can set one Connection String value in the child package, commit the package to revision control and be confident the Production, Test, etc configuration value will be used when the package executes. Furthermore, if all the developers on a team have identical properties for local execution, the values can remain set in the child package for the developer configuration, and overridden with the correct Production, Test, etc configuration at execution in those environments.
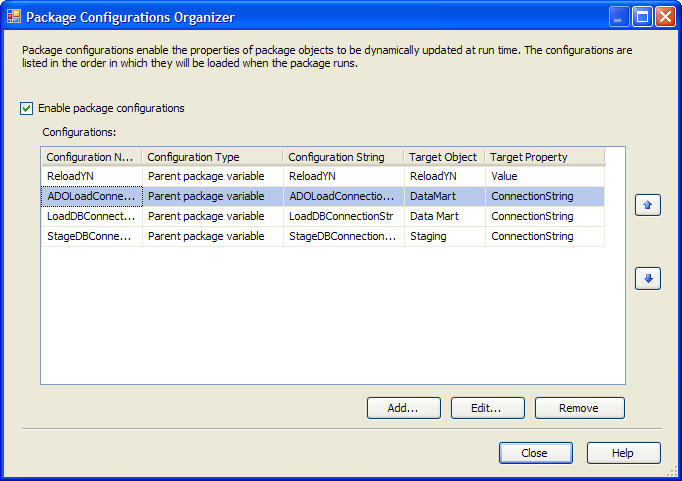
The final shot of setting the Connection String for the Data Mart connection manager is below. If you have any suggestions or questions please post a follow-up. Oh, the tie in to the post headline: Basically set the Package Configuration Properties as close as you can to the intended property.
In a recent effort to use SSIS for the ETL processing of a data mart, I found a need to manage different configurations between production, test and individual developer sandboxes. This is the nail for which package configurations is the hammer. It soon became apparent that while we had indeed implemented "a" way of say, managing the different connection strings, for example. Time would tell that we had missed something significant.
Our initial strategy had been to use Parent Package configurations t
 o set the Value property of the Connection String to the correct server, catalog, etc. It turns out this works, but is not without it's disadvantages. When you try to edit the package configured in this way, it is necessary to put the connection string in the Connection String Value property, because you are not in the execution environment, none has been set from the Parent Package. Additionally, Expressions have to be used with the Connection Manager to accomplish the setting of the target value property with the parent package variable. This is further complicated by having to 'remove' this Connection String value before committing the package to version control, lest the SSIS Server attempt to connect to the developer machine and not the server indicated by the package configuration.
o set the Value property of the Connection String to the correct server, catalog, etc. It turns out this works, but is not without it's disadvantages. When you try to edit the package configured in this way, it is necessary to put the connection string in the Connection String Value property, because you are not in the execution environment, none has been set from the Parent Package. Additionally, Expressions have to be used with the Connection Manager to accomplish the setting of the target value property with the parent package variable. This is further complicated by having to 'remove' this Connection String value before committing the package to version control, lest the SSIS Server attempt to connect to the developer machine and not the server indicated by the package configuration.The better solution, it turns out, is to assign the Parent Package variable directly to the Connection String. This way, the true power of runtime package configuration is reali
 zed. Using this method, a developer can set one Connection String value in the child package, commit the package to revision control and be confident the Production, Test, etc configuration value will be used when the package executes. Furthermore, if all the developers on a team have identical properties for local execution, the values can remain set in the child package for the developer configuration, and overridden with the correct Production, Test, etc configuration at execution in those environments.
zed. Using this method, a developer can set one Connection String value in the child package, commit the package to revision control and be confident the Production, Test, etc configuration value will be used when the package executes. Furthermore, if all the developers on a team have identical properties for local execution, the values can remain set in the child package for the developer configuration, and overridden with the correct Production, Test, etc configuration at execution in those environments.The final shot of setting the Connection String for the Data Mart connection manager is below. If you have any suggestions or questions please post a follow-up. Oh, the tie in to the post headline: Basically set the Package Configuration Properties as close as you can to the intended property.
Friday, January 20, 2006
Data, Data Everywhere
I have spent the better part of the last 20 years working on software projects that leveraged, in one way or another a database. Software that analyzed banking customer profitability, retail sales, phone switch records, help desk tickets for a telephone utility, disease management, logistics to name a few. That doesn't even consider the torrent of data being generated by activity on the Web or RFID. What is a business to do with all of this data? How are decision makers going to stay afloat in this flood of data? How are managers going to find meaning (information) from the bits and bytes?
Presently, there are data structures that can address part of this problem. Data Warehousing/Mart structures permit users to conduct hypothesis verification. For example, division manager postulates "Widgets and Hoohas are draining our profitability". She can then proove or disprove the theory via inquiry of the Financial Data Mart, for instance.
This simply will not be suffiicient in the very near future. As more and more databases, come online, the manager will require a smarter way of using the data. Data Mining, using statistical and other modeling techniques to find patterns and relationships not readily apparent to even the knowlege worker, is how organizations may distance themselves from competition and draw themselves nearer to their partners and supply chain.
Presently, there are data structures that can address part of this problem. Data Warehousing/Mart structures permit users to conduct hypothesis verification. For example, division manager postulates "Widgets and Hoohas are draining our profitability". She can then proove or disprove the theory via inquiry of the Financial Data Mart, for instance.
This simply will not be suffiicient in the very near future. As more and more databases, come online, the manager will require a smarter way of using the data. Data Mining, using statistical and other modeling techniques to find patterns and relationships not readily apparent to even the knowlege worker, is how organizations may distance themselves from competition and draw themselves nearer to their partners and supply chain.
Subscribe to:
Comments (Atom)
